Web scraping is a mechanism to crawl web pages using software tools or utilities. It reads the content of the website pages over a network stream.
This technology is also known as web crawling or data extraction. In a previous tutorial, we learned how to extract pages by its URL.
View Demo
There are more PHP libraries to support this feature. In this tutorial, we will see one of the popular web-scraping components named DomCrawler.
This component is underneath the PHP Symfony framework. This article has the code for integrating and using this component to crawl web pages.
We can also create custom utilities to scrape the content from the remote pages. PHP allows built-in cURL functions to process the network request-response cycle.
About DomCrawler
The DOMCrawler component of the Symfony library is for parsing the HTML and XML content.
It constructs the crawl handle to reach any node of an HTML tree structure. It accepts queries to filter specific nodes from the input HTML or XML.
It provides many crawling utilities and features.
- Node filtering by
XPathqueries. - Node traversing by specifying the HTML selector by its position.
- Node name and value reading.
- HTML or XML insertion into the specified container tag.
Steps to create a web scraping tool in PHP
- Install and instantiate an HTTP client library.
- Install and instantiate the crawler library to parse the response.
- Prepare parameters and bundle them with the request to scrape the remote content.
- Crawl response data and read the content.
In this example, we used the HTTPClient library for sending the request.
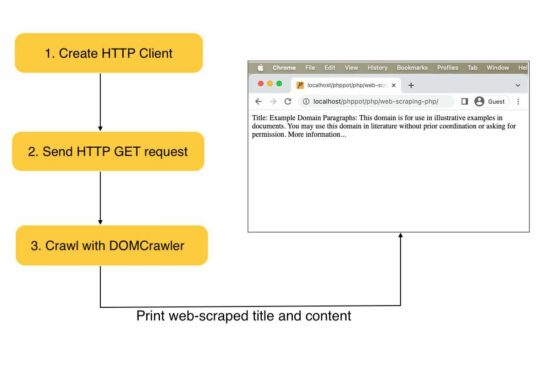
Web scraping PHP example
This example creates a client instance and sends requests to the target URL. Then, it receives the web content in a response object.
The PHP DOMCrawler parses the response data to filter out specific web content.
In this example, the crawler reads the site title by parsing the h1 text. Also, it parses the content from the site HTML filtered by the paragraph tag.
The below image shows the example project structure with the PHP script to scrape the web content.
How to install the Symfony framework library
We are using the popular Symfony to scrape the web content. It can be installed via Composer.
Following are the commands to install the dependencies.
composer require symfony/http-client symfony/dom-crawler
composer require symfony/css-selector
After running these composer commands, a vendor folder can map the required dependencies with an autoload.php file. The below script imports the dependencies by this file.
index.php
<?php
require 'vendor/autoload.php';
use Symfony\Component\HttpClient\HttpClient;
use Symfony\Component\DomCrawler\Crawler;
$httpClient = HttpClient::create();
// Website to be scraped
$website = 'https://example.com';
// HTTP GET request and store the response
$httpResponse = $httpClient->request('GET', $website);
$websiteContent = $httpResponse->getContent();
$domCrawler = new Crawler($websiteContent);
// Filter the H1 tag text
$h1Text = $domCrawler->filter('h1')->text();
$paragraphText = $domCrawler->filter('p')->each(function (Crawler $node) {
return $node->text();
});
// Scraped result
echo "H1: " . $h1Text . "\n";
echo "Paragraphs:\n";
foreach ($paragraphText as $paragraph) {
echo $paragraph . "\n";
}
?>
Ways to process the web scrapped data
What will people do with the web-scraped data? The example code created for this article prints the content to the browser. In an actual application, this data can be used for many purposes.
- It gives data to find popular trends with the scraped news site contents.
- It generates leads for showing charts or statistics.
- It helps to extract images and store them in the application’s backend.
If you want to see how to extract images from the pages, the linked article has a simple code.
Caution
Web scraping is theft if you scrape against a website’s usage policy. You should read a website’s policy before scraping it. If the terms are unclear, you may get explicit permission from the website’s owner. Also, commercializing web-scraped content is a crime in most cases. Get permission before doing any such activities.
Before crawling a site’s content, it is essential to read the website terms. It is to ensure that the public can be subject to scraping.
People provide API access or feed to read the content. It is fair to do data extraction with proper API access provision. We have seen how to extract the title, description and video thumbnail using YouTube API.
For learning purposes, you may host a dummy website with lorem ipsum content and scrape it.
View Demo