I know, I know! How can you put PHP and Fast in the same line? I would say, you are stuck in the past. You should try PHP 7 and experience it yourself. There will be a lot of criticism for this article. Kindly read through.
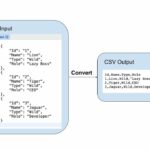
LOAD DATA INFILE is the best option to import a huge CSV file. In this article we are going to see how we are going to read a CSV file and INSERT records via PHP script. This can be used in such a special case.
In general PHP will not have such use cases. But you never know, when you will come across such a situation, a client requirement can come any time. When you are a “freelance programmer” (not playing a consultant role), you will be thrust upon with all sorts of crazy requirements.

I have written an article about all things CSV in PHP. You should go through that to learn about handling CSV files in PHP.
I am well aware about the micro-benchmarking and its pitfalls. So, I didn’t go in that direction for this articles. That’s why I have given in the title as just seconds. It’s an approximation. This is not for people who are going to see in micro, nano seconds.
If you want to insert a million records in few seconds, using PHP script programmatically, then this will definitely help. The use case is rare and so the solution. You may have to do some tweaks here and there in this sample code to fit for your case.
<?php
function file_get_contents_chunked($link, $file, $chunk_size, $queryValuePrefix, $callback)
{
try {
$handle = fopen($file, "r");
$i = 0;
while (! feof($handle)) {
call_user_func_array($callback, array(
fread($handle, $chunk_size),
&$handle,
$i,
&$queryValuePrefix,
$link
));
$i ++;
}
fclose($handle);
} catch (Exception $e) {
trigger_error("file_get_contents_chunked::" . $e->getMessage(), E_USER_NOTICE);
return false;
}
return true;
}
$link = mysqli_connect("localhost", "root", "pass", "huge-csv");
$success = file_get_contents_chunked($link, "sample-dataset.csv", 2048, '', function ($chunk, &$handle, $iteration, &$queryValuePrefix, $link) {
$TABLENAME = 'tbl_lead';
$chunk = $queryValuePrefix . $chunk;
// split the chunk of string by newline. Not using PHP's EOF
// as it may not work for content stored on external sources
$lineArray = preg_split("/\r\n|\n|\r/", $chunk);
$query = 'INSERT INTO ' . $TABLENAME . '(id, name, email) VALUES ';
$numberOfRecords = count($lineArray);
for ($i = 0; $i < $numberOfRecords - 2; $i ++) {
// split single CSV row to columns
$colArray = explode(',', $lineArray[$i]);
$query = $query . '(' . $colArray[0] . ',"' . $colArray[1] . '","' . $colArray[2] . '"),';
}
// last row without a comma
$colArray = explode(',', $lineArray[$i]);
$query = $query . '(' . $colArray[0] . ',"' . $colArray[1] . '","' . $colArray[2] . '")';
$i = $i + 1;
// storing the last truncated record and this will become the
// prefix in the next run
$queryValuePrefix = $lineArray[$i];
mysqli_query($link, $query) or die(mysqli_error($link));
/*
* {$handle} is passed in case you want to seek to different parts of the file
* {$iteration} is the section of the file that has been read so
* ($i * 4096) is your current offset within the file.
*/
});
if (! $success) {
// It Failed
}
Two main things to note are,
- Read the file in chunks (batch).
- Insert multiple records in a single insert statement.
The above is key in speeding up the overall process. Reading line by line and iterating through a loop will slowdown the process. So everything boils down to reading chunks (batches) and multi insert. Then a third point worth mentioning is use PHP native functions wherever possible.
I have used a Regex to replace newline in the CSV file. If you got a better option please suggest via comments section below.
Now let me walkthrough the code.
PHP’s fread allows to read in chunks of strings. Try experimenting with different chunk (batch) sizes. There is no particular right size. There are lots of variables, your server configuration, hardware, MySQL setup and lot more.
I have used a sample CSV file which I generated myself. I will detail the process below. You can use your own sample or real data and pass that as a parameter.
file_get_contents_chunked does the processing of CSV file and this has a callback function as the last argument. This callback takes care of parsing the record by the delimiter (comma in my example) and creating the multi-insert query and doing the actual insert.
You may have to modify the query part to suit your database table format. The overall structure of the script takes care of parsing the CSV in chunks (batches) and callbacks. Thanks to RobertPitt.
One thing worth mentioning is, instead of reading line by line I have used the chunk as it is to improve the speed. All through the Internet users have suggested fgetcsv. But I have gone ahead with chunk (batch) read of fread.
The fread when reading as chunk (batch) it will obviously have part a part of a CSV row truncated. I have stored that truncated last record in each chunk in $queryValuePrefix variable. It is retained by declaring as a reference via callback.
Sample CSV dataset
I wrote a tiny PHP script to generate the required CSV dataset. There are a lot of sources like Government census record, now popular Covid data, weather data and lot more.
At this time of Artificial Intelligence era, where Data Mining is more popular than Twinkle Twinkle Little Star, getting a sample huge CSV file is just a click away.
But still for flexibility, I wrote the PHP script myself.
<?php
$file = fopen('s-sample-dataset.csv', 'w');
for ($i = 1; $i <= 1000000; $i ++) {
echo $i;
$line[] = $i;
$line[] = uniqid();
$line[] = uniqid();
fputcsv($file, $line);
$line = null;
}
fclose($file);
This is a ruthless way of generating a sample data :-) At this juncture Faker is worth mentioning. It is a good PHP library for generating nice fake data. It will look very close to real.
Last, for the nerds. This script ran and imported one million (1000000) records in 9 seconds. My machine is a MacBookPro with Catalina, 2.3 GHz i5, 16 GB RAM and PHP 7.4. This is just for an idea and please do not make much out of this.
Pour in all your view points and suggestions for improvement in the below comments. Happy parsing all your CSVs, chunk it out!



Thanks you for sharing
We are facing same issue to import large size CSV file.
Welcome Nikunj. Try this solution and post your feedback.
What a brilliant technique, thank you, this helped me out a lot.
Welcome Danny.
Hi, only a tip: in for loop you have 100.000, not a million…
Hi Angel,
Thank you for pointing out. It is a typing error and I have fixed it now. Thanks.
Interesting code and works great with the sample code thanks. Modded slightly to add an file upload (your previous sample code for small csv uploads).
I can’t get it to read a more complex set though. Mine is 14 rows across – seems to error on the second chunk read. When importing a few 100 records its great – but on the full 70k set it errors.
Made it more simple version to test with 3 rows but still same error when reading the 70k file.
You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘””,””),(734,”22361″,”0″),(735,”22368″,”0″),(736,”22382″,”0″),(737,”22390″,”0″),(‘ at line 1
Any ideas please?
Thanks
Rich
Hi Rich,
Thanks. Need more information. Can you email me the data set that you are using and I can help you out.
Is there any solution for check data already exists in mysql database with this source code, because We have import large csv file with check duplicate data in database, can you give any idea?
Hi Riyaz,
If I understand your requirement, you need to check for already existing record and then import. This script will support that, but you need to make changes to it. May be I will post an update on this article as time permits.
You can try to use “ON DUPLICATE KEY UPDATE”. It will check if the record is already exist. But you need to create a unique index(may be a single column or combination of columns) to trigger the on Duplicate.
INSERT INTO table-name (column1, colume2, column3)
VALUES (value1, value2, value3)
ON DUPLICATE KEY UPDATE
column1 = VALUES(value1);
The above query will do three things:
1) Insert new rows
2) check existing rows
3) Update row if already exist
I hope it will help.
it works great with your example. But when I try to do it for my table, (my first column is varchar), it goes blank. Is there anywhere in the script where int or varchar is denoted which I am missing.
Thanks Brajesh.
There is no specific configuration like that. If you can give me more information or post your sheet and I can help you out.
Hi,
My data format is like this
35457,Hatinder Kaur-9811130738,Hatinder,Kaur,,9811130738,Active,”2618, B S Lan 9, Chuna Mandi, Paharganj
New Delhi, 110055″,,New Delhi,Delhi,India,,”2618, B S Lan 9, Chuna Mandi, Paharganj
New Delhi, 110055″,”Paharganj
New Delhi, 110055″,New Delhi,Delhi,India
My single column value is like “2618, B S Lan 9, Chuna Mandi,
Paharganj
New Delhi, 110055”. As this has new line value it is considered as next row when splitting. Is there any way to clear this out. It’s an urgent work. Please help me ASAP if anyone can.
Hi Vidya,
You need to escape the newline value before processing.
it works great with speed. I just have issue with the last row of each batch. Sometimes it doesn’t read complete row (Just half row) and not skipping the header row.
Rest all is great and Thank you very much for this great post.
Welcome Darshana.
To skip the first header row, you need to add a loop iterator and skip the first occurence.
Thank you for sharing. In your code where is step 7 – Clear all memory references?
In this context, closing the file handle is clearing all the memory references.
This works great, thanks! However, if my csv file has field names in he the first row, how do I NOT include that in the very first query?
Hi Brad,
Thanks. You should declare a loop iterator variable before the start of the loop. The for the first iteration skip processing the record. This will help you to exclude the first row if it has field names.